



Retrieval augmented generation has emerged as the technology of choice for building trustworthy enterprise GenAI solutions, largely due to its capacity to outperform fine-tuned large language models (LLMs) in performance, accuracy, and reliability. However, maximizing this value requires a solid grasp of the underlying architecture. This guide demystifies the components of a RAG architecture and highlights how to extend its capabilities to meet complex enterprise needs — helping you build an enterprise GenAI roadmap that accelerates time-to-value and scales securely.
Visual Overview: RAG Architecture Diagram
What is retrieval augmented generation (RAG)? In its simplest form, a RAG architecture comprises two functional blocks: one for information retrieval and one for response generation. The system first retrieves relevant information from a knowledge base, providing crucial context to the LLM, which then uses that information to generate a response.
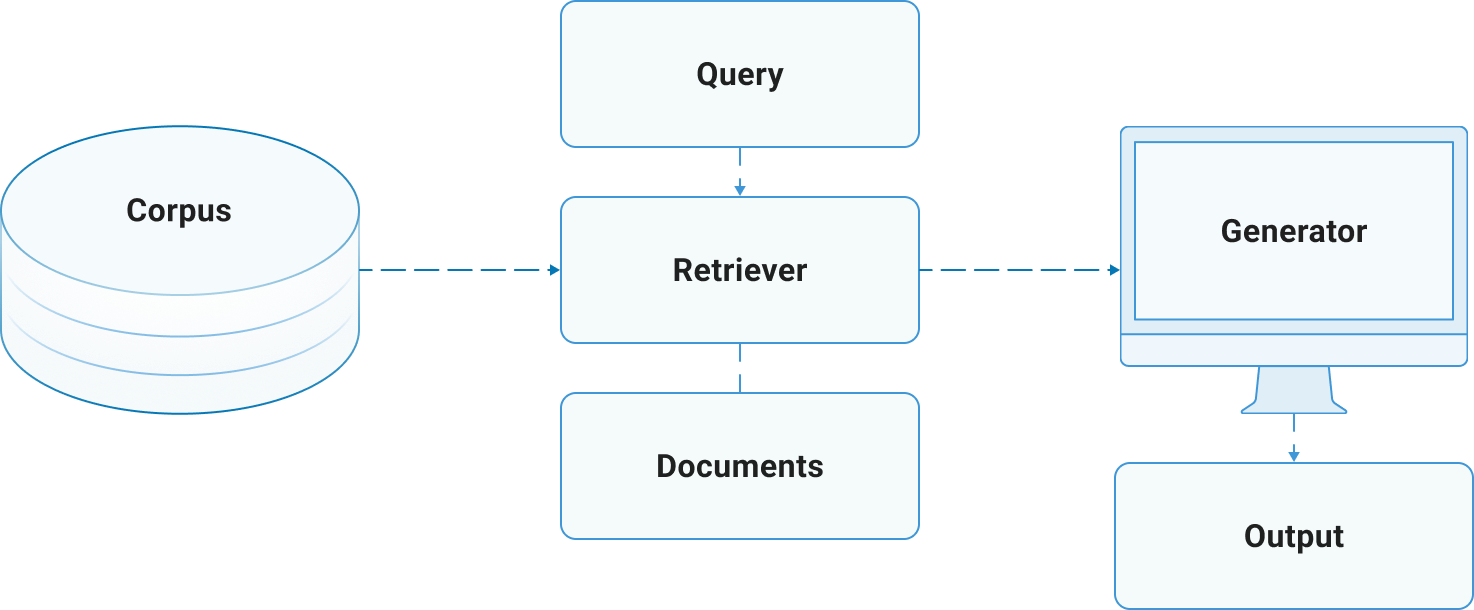
Even sophisticated RAG implementations that are relied on in enterprise settings – and which we will explore later in this blog post –rely on this underlying architecture.
Core Components of the RAG Architecture
Now, let’s drill deeper into each of these two functional blocks, starting even further upstream, with data ingestion and indexing, processes that need to be carried out long before a user even submits a query.
Indexing Pipeline
This initial stage is crucial for preparing your data for the RAG system.
- Data Ingestion: The process begins by ingesting documents and data from various sources, such as files, databases, or APIs.
- Data Preprocessing: The ingested data is then cleaned and transformed to make it suitable for augmentation. This can include converting PDFs to text, normalizing data, and expanding abbreviations.
- Chunking: Next, documents are divided into smaller, manageable pieces to facilitate efficient indexing and retrieval. Effective chunking strategies can also reduce the cost of retrieval and generation by only including the relevant portion of a document in the prompt.
- Vectorization: Each chunk of data is converted into a numerical representation called a vector using an embedding model. The direction of these vectors in multi-dimensional space represents the semantic meaning of the text.
- Indexing: The vectorized data chunks are stored in a searchable database, most commonly a vector database. This index allows for quick and "fuzzy" searches based on relevance.
Once the data is prepared, the RAG system's operational flow involves the two primary engines outlined in the previous section:
- The Retriever: This component uses a hybrid search approach to find the most relevant data chunks from your indexed database. It combines vector search to find documents with similar meaning and keyword search for exact matches. The results are then combined, ranked, filtered, and passed to the generation stage.
- The Generator: This is comprised primarily of the LLM that takes the user’s original query and the retrieved information to produce a coherent and contextually appropriate answer.
How the RAG Architecture Works (Step-by-Step)
Let's follow a user's query through the system to see the architecture in action.
- User Query Input: The process is initiated when a user enters a query into the system.
- Query Embedding: The user's query is also converted into a vector representation using the same embedding model used during the indexing stage.
- Retrieval: The system performs a search on the vector database to find the top k most relevant chunks that semantically match the user's query. This is often a hybrid search that combines vector search with keyword search for better accuracy.
- Prompt Augmentation: The retrieved documents are then used to "augment" the user's original prompt. This creates a new, enriched prompt that provides the LLM with the necessary context.
- Generation: The augmented prompt is sent to the LLM, which uses the provided context to generate a coherent, factual, and contextually appropriate response.
- Response: The final response is delivered to the user.

Architectural Variations and Alternatives
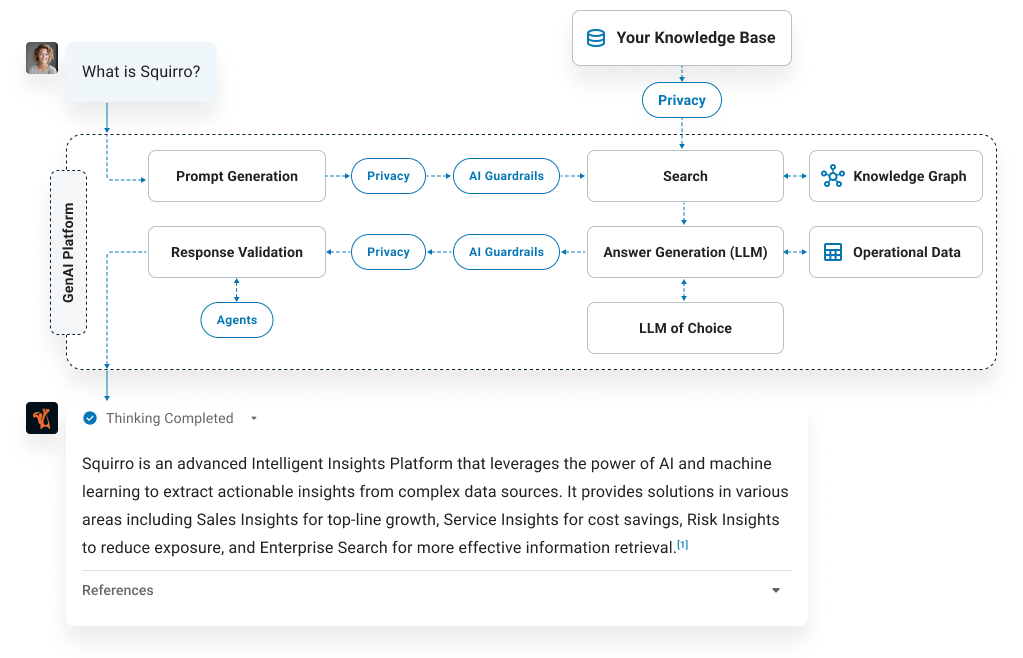
While standard RAG is effective for many use cases, its effectiveness is limited by factors like data quality, the amount of context the LLM can incorporate, and its ability to validate results. For complex tasks that go beyond simply answering a query, additional components are required. The Squirro Enterprise GenAI Platform addresses these limitations by integrating several additional components that extend RAG's capabilities.
- Agent Framework: This component allows for the creation of autonomous, task-specific tools that enrich AI workflows and enable complex use cases. For example, it can be used to automatically retrieve information from Wikipedia to augment a query.
- Knowledge Graphs: By revealing hidden data hierarchies and relationships, knowledge graphs increases AI accuracy, particularly for complex information.
- Operational Data: Combining access to both first- and third-party structured data makes it possible to integrate real-time operational data into RAG applications.
- AI Guardrails & Privacy Layer: These components ensure reliable, ethical, and compliant decision-making while safeguarding sensitive data. The Privacy Layer ensures that personally identifiable information (PII) is not passed on to the LLM.
Enhanced RAG solutions can achieve outcomes that are far beyond the capabilities of out-of-the-box RAG.
Enterprise Use Cases and Deployment Models
The Squirro Enterprise GenAI Platform has been used to address complex use cases that go beyond the limits of stand-alone RAG.
- Highly Accurate Data Retrieval: A food service company needed a conversational AI solution to provide highly accurate, deterministic outputs regarding allergens in customized orders. The solution combined an Agent Framework with a knowledge graph to achieve up to 90% accuracy.
- Automated Competitive Intelligence: A European energy company automated the generation of a daily market intelligence report, a task that would typically require hours of manual research. This was achieved using the Agent Framework to define the business logic for monitoring, ingesting, and summarizing information from hundreds of sources.
- Automated Customer Interactions: An international telecommunications company used a knowledge graph to facilitate the classification of customer support requests and systematically gather all necessary information before automatically generating a service ticket. This helps avoid follow-up requests for missing information, which can negatively impact customer satisfaction.
These examples demonstrate that while RAG enhances an LLM's ability to locate specific data, it requires additional technological components to handle complex tasks that deviate from the standard format of responding to user queries.
=> Learn more in our white paper on “Advancing Generative AI Beyond RAG.”
RAG Architecture Best Practices (2026 Edition)
Building a RAG system in 2025 that is able to scale with your business requires a tried and tested approach to architecture and implementation. The following best practices are crucial for ensuring a high-performing and reliable enterprise GenAI application.
- Modular Design for Flexibility and Scalability: A modular architecture lets you swap out individual components, such as different LLMs, embedding models, or vector databases, as new and improved technologies emerge. This design provides the flexibility needed for future-proofing your system, adapting to changing regulatory requirements, and meeting scaling demands.
- Robust Data Quality Assurance: The performance of any RAG-powered application is directly dependent on the quality of the data in the knowledge base. To ensure recency and accuracy, all data needs to be correctly ingested, preprocessed, and validated to ensure consistency. Running tests and validations is a critical part of this process.
- Security and Data Privacy: In highly regulated enterprise settings, security and data privacy are a non-negotiable entry ticket for generative AI applications. The architecture should include a Privacy Layer to ensure that corporate and customer data, particularly personally identifiable information (PII), are protected and not passed on to the LLM. Additionally, AI Guardrails should be implemented to ensure reliable, ethical, and compliant decision-making.
- Observability and Monitoring: To maintain system health and performance, it is essential to monitor key metrics, including retrieval quality, system latency, and token usage. This allows for proactive identification and resolution of potential issues and enhances transparency and trust by providing a clear view of how responses are generated.
- Addressing Inherent RAG Limitations: While RAG is powerful, its out-of-the-box capabilities have limitations, such as handling complex tasks and validating generated results. The most robust enterprise solutions leverage additional components like Knowledge Graphs and an Agent Framework to reveal hidden data relationships and execute autonomous tasks, respectively.
Conclusion: Architecting a Future-Proof RAG System
As organizations integrate generative AI into their operations, RAG stands out as a key enabler for reliable, accurate enterprise AI solutions. While RAG enhances the capabilities of LLMs by leveraging additional knowledge bases, it requires additional enabling technologies to handle more complex tasks.
The Squirro Enterprise GenAI Platform demonstrates how a future-proof RAG system can be built by extending core RAG functionalities with components like the Agent Framework, Knowledge Graphs, and a Privacy Layer, enabling fully sovereign AI solutions. By doing so, you can ensure your enterprise GenAI applications are not only reliable and accurate but also capable of addressing your most critical business challenges.
Are you ready to architect a RAG solution that drives innovation and enhances your company's competitiveness?
Book a demo to see how an enhanced RAG solution can work for you. And download our white paper on Advancing GenAI Beyond RAG to learn how to leverage Enhanced RAG to develop advanced GenAI applications.



