Join SWIFT’s CIO for a Live Webinar on Enterprise AI Adoption and Risk Mitigation | Monday, July 28 | Save Your Spot Now
Discover the most recent featured publicationsand get inspired by the best of Squirro
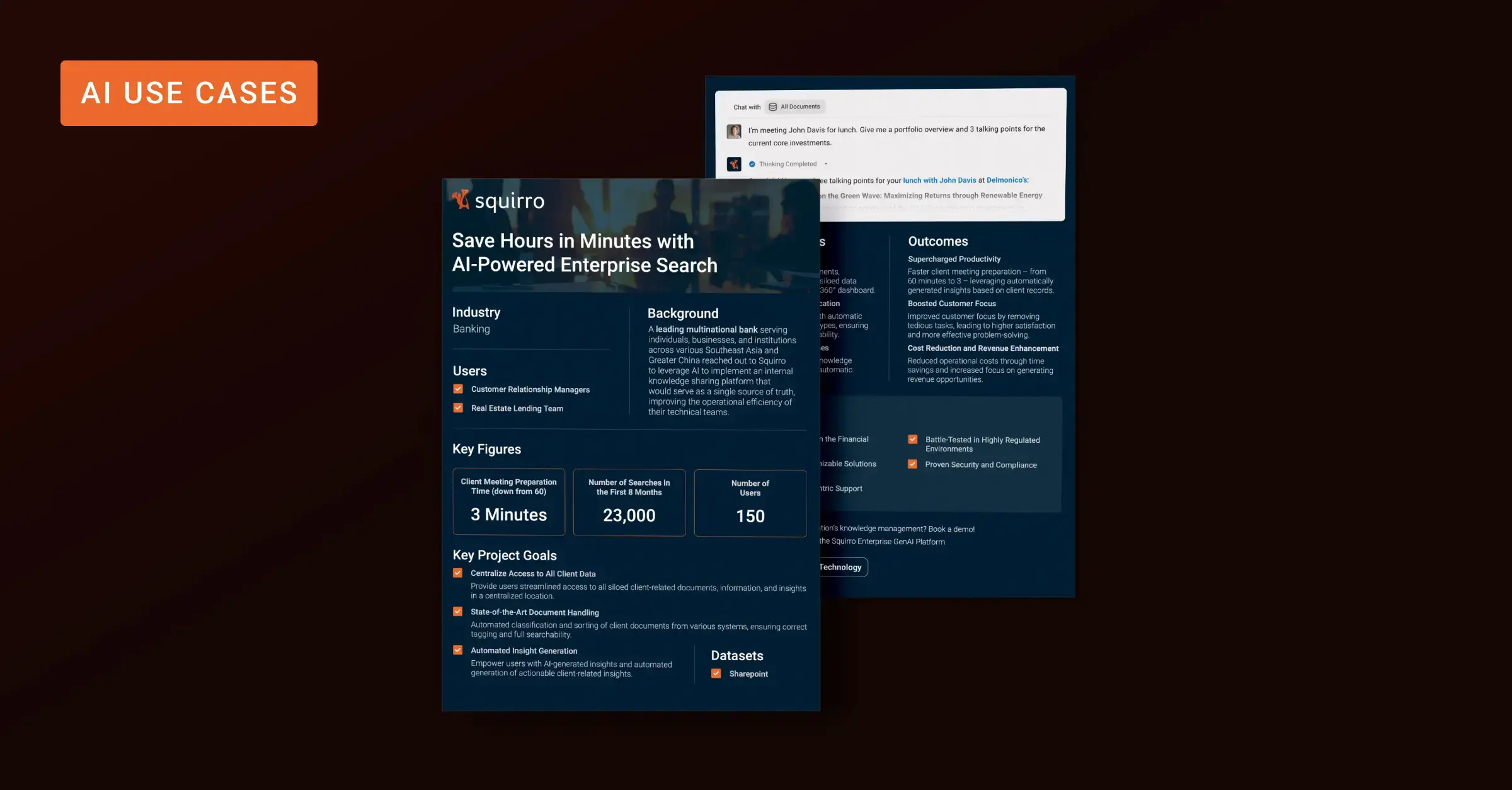
Closing the Gap in Generative AI Accuracy